
The Year of AI: Navigating the Power, Influence, and Future Unseen Risks of Tech Giants' Control
It’s not a reach to state that due to the massive spike in popularity within the common discourse, Artificial Intelligence (AI) got in 2024, 2025 is likely to be “The Year of AI”.

Google Trends of Search Term “AI” in Past 5 Years
Lately, everyone who is anyone has likely flooded your feeds with personal analyses and op-ed articles about AI, so I'll do my best not to repeat myself.
Most conversations about AI fall roughly into two groups: those enthusiastic about the technology and those fearing a coming doomsday.
I want to tackle this discourse using a slightly different approach.
Let’s begin, for the sake of argument, by assuming that AI will truly be beneficial to future businesses.
Let’s also assume that the world’s legislators will have a real proactive willingness, capacity, and knowledge to create proper regulations to protect us from the abuse and/or the misuse of AI; deep fakes being at the top of my personal list of concerns.
Keeping those two assumptions in mind, I want to focus today on who will actually be in control of this technology and the associated consequences of that control.

In the past, we’ve already seen situations where a single company had some kind of monopoly on a particular product. Some of the most prominent examples in the tech space were of course Intel with its CPUs, and Microsoft with their PC operating system or office productivity packages.
Over time, their monopolies faced challenges from competitors such as Advanced Micro Devices (CPUs) and open source options like Linux and OpenOffice.
In both cases, the investments necessary for the competitors to come with an equivalent product were relatively medium to low. We are of course still talking about millions of dollars of capital poured into infrastructure and/or human resources, but within the scale of global business, especially with the numbers we’re seeing today, the economic barrier for entry was still, in my opinion, medium to low.
In addition, these products were just tools without a “character” or any kind of unpredictable behavior. They were ready “out of the box” for the customers to use as they wished. When faced with the same input, they generated the same output. If you pressed the letter “e”, it didn’t matter what keyboard you were on, what kind of computer you were on, if you typed it using Microsoft Office software using a PC or on a Linux device using OpenOffice, it didn’t matter. The output was still a typed “e”. They were simple, transformational, tools: a physical action (e.g. typing) which produced a physical, constant result (e.g. a letter) reproducible any number of times in the exact same way.
Now, let’s talk about AI.
A fundamental piece for the creation of AI models is their training. This is a gigantic step where a massive amount of data is processed by the AI’s algorithms to fine tune its models. Once the model is trained and validated, it is ready for deployment and adoption. A good way to think about it is more or less as the equivalent of a fashion designer’s efforts when creating a new kind of fabric: many hours of trial and error to finally get the final sample. After that, the product is adopted at scale by tailors or other designers to create clothes that use that fabric as a base.

Training an AI module is extremely expensive and takes a very long time. This is due to the amount of data that needs to be processed and the complexity of the algorithms. We are talking about millions and millions (maybe billions) of records and each record has billions of fields (parameters) to be processed. ChatGPT-4 is estimated to have around 1.76 to 1.8 trillion parameters.
In order to complete this fundamental process, you need extremely powerful computational ability. Also consider that the training for any AI module requires several iterations before achieving the expected results. It’s not just a “one-and-done” situation.

Here is where Graphics Processing Units (GPUs) step into play. These specialized processors are designed for the optimization of parallel computing. The GPU was originally designed and introduced and deployed in high end video controllers.
GPUs allow a spike in the computational capacity of servers and so significantly reduce the training time needed for AI models despite the complexity of the algorithms, even if the amount of input data keeps increasing.
The undisputed leader of GPUs manufacturing is Nvidia (H100, H200).
Now is when a few monetary facts become important for our conversation:
A single H100 card may cost $25000 retail price. The H200 is around $30000 a piece.
Bulk orders usually come with a discount.
The typical usage of the GPU cards is to plug 6 to 8 of them in a single server.
Companies that are leading the charge in the development and exploration of AI models (OpenAI, Microsoft, Google, Facebook, etc.), therefore need to purchase GPU’s in the scale of thousands in order to keep up with their internal demands as well as the demand of the customers that are employing their AI models.
The current estimate is that Nvidia has sold around 2 million H100 GPUs in just 2024.
OpenAI Sora’s video tool large-scale deployment uses 720,000 NVIDIA H100 GPUs worth $21.6 billion.
Elon Musk said XAI was using 20,000 Nvidia H100s to train Grok 2. (around $600 million of value)
Just Facebook and Microsoft ordered 150,000 GPUs in 2024 alone ($4.5 billion investment)
Microsoft plans for a $80 billion investment in AI-ready data centers ($45 billion in USA) in 2025


These are just the simple material costs. The operational costs of these GPUs is another financial bomb. Their need for electric power is impressive. According to a recent report by Deloitte, AI adoption is projected to drive data center electricity consumption to 2,000 TWh by 2050. To compare, according to data from the US Energy Information Administration, a city of 100,000 inhabitants would typically consume around 1.2 Terawatt-hours (TWh) of electricity per year, based on the average US per capita consumption of approximately 12 Megawatt-hours (MWh) per person.
Electricity is certainly not cheap.
Of course, any machinery that is placed in a data center also requires a sophisticated system of cooling to keep them functional and avoid overheating damage, which is another nightmare of costs involving additional water, power, and air/ventilation, among others. All of this does not include real estate and manpower costs: the architects, builders, managers, etc., needed to actually build the data centers, and then the employees needed to run and maintain them. Truckloads and truckloads of cash.
In addition to the huge investment required to be in the AI business at all, we need to consider the intrinsic nature of the product.
Compared to any previous software seen on the market, an AI model isn’t just a passive transformative piece of software, like we mentioned above. They’re a complex set of systems that interpret input data based on the data banks used for their training. They then extrapolate this data to either answer a question or produce a requested result.
Therein lies the danger. Many exchanges with an AI model begun by using language (i.e. a written prompt), the model then interprets that language based on its framework, (i.e. the specific data bank that was used for its training), and offers a result based on that extrapolation. The well-studied presence of bias in written and spoken human language means that bias is introduced both at input and during individual interpretation of each output. Most importantly, however, the nature of the training data informs any output an AI model produces. The very nature of AI optimization means selection and filtering of known information.

AI interaction is governed entirely by the engineers employed by the corporations creating the models. These engineers control response generation, training methodologies, and, subsequently, the content produced, all of which are shaped by their choices and directions.
The bottom line is that we, as a society and as a global economy, are going to be leveraging these tools with increasing dependence. It’s inevitable. Any company or enterprise that fails to do so will otherwise automatically lose any chance of economic competitiveness and relevance on the market. However, the investment required to even get your foot in the door of this exclusive club of companies that is working in this space is so huge, no government or research center can easily be part of it. We are going to depend more and more on this restricted group of private, stock market biased enterprises that will see their power and influence growing day after day. Their revenues already exceed the GDP of medium size states today and their political influence is evident by just reading the news.

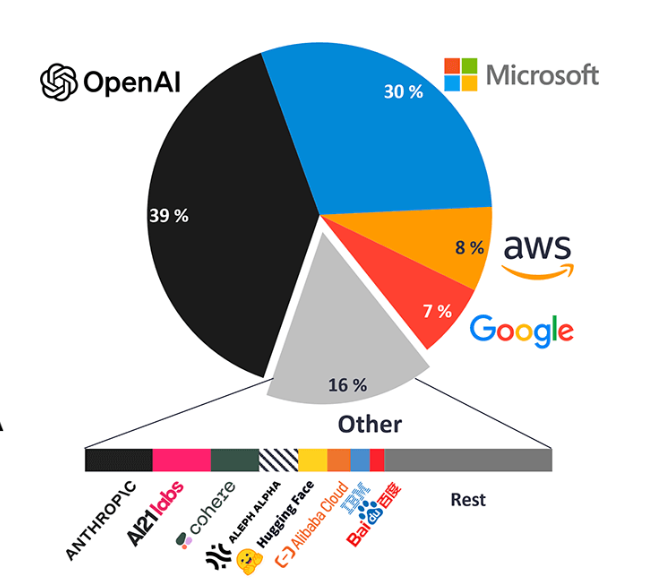
Leading Generative AI Companies
This is the real danger the governments and everyday people should worry about, in my opinion.
As you know, the members of the board of a company like the ones we are talking about are elected by the stakeholders that have a direct economical interest in the company's success. Their goal is not the welfare of the general population, but of their stock portfolio. History has already taught us plenty of times that human greed is limitless and so handing unlimited power and influence to these tech giants by making their products a staple of our modern life and economy is not a future we should pursue or encourage.
If, and when, the adoption of AI tools will become so essential and pervasive to day-by-day activities of even the smallest enterprise, both in business and leisure, our dependency will make us slaves of these tech giants. We will use those tools for any personal or business decision, and so they will have a voice in every one of those decisions, no matter how small.
But this could be a good thing, you may say, if the tools are so useful!
Not a chance. Remember what an AI model is: a statistical model that processes an immense amount of data and identifies the combination of data with the highest percentage rate to satisfy your original question. It has no clue about the meaning of what it reports to you. It certainly doesn’t have a moral compass or a conscience that can reflect on the content of its responses. Yes, their designers may add checks and balances within their models, but it’s completely up to them how much to limit, or not limit, the model.
In addition, as AI models become ubiquitous, user trust will grow, overshadowing the importance of the very real bias issues embedded within these models. This has already happened just in our lifetime. When’s the last time you asked yourself if your word processor’s spellcheck was actually giving you the right grammatical answer, or if Google Maps was actually giving you the correct route to your destination?

Consider this: A model trained primarily on soccer data will statistically be unlikely to include information about other sports when responding to general sports questions. Should AI models achieve such prevalence that their outputs are accepted without scrutiny, a direct influence on their users is certain.
One can, of course, extend this example to the sponsoring of a particular product, or even political opinions.
Presently, the onus of ensuring the quality and balance of training data rests with technology companies. It is reasonable to assume that vested interests play a substantial role in a company's AI development programs.
All of this, however, doesn’t mean AI models cannot be useful.
I’ll use another example to explain. The process for training an AI model is like taking a massive amount of information and breaking it into billions of tiny puzzle pieces that retain their connections to one another. Thus, the term “home” might hold a connection to your house, the baseball diamond's base, or your childhood residence.
In formulating a response to your question or prompt, a model prioritizes pieces with the highest statistical relevance rate to each other and reconstructs an answer based on the strongest statistical relationships among those pieces. Therefore, it may take pieces from very different sources in order to put together the final report, likely in a combination you’ve never thought about.
This is positive in the sense I can potentially get a piece of knowledge from a source I never had access to, therefore increasing my overall know-how or offering a solution that is new to me, or one that I would never have thought of otherwise. The biggest pro, of course, is that it provides this solution with no need for me to expend my own time or energy.
It is important to note, however, that the model did not create this information from scratch. The large puzzle pieces were simply rearranged, resulting in a new and possibly original pattern. The inverse of that, of course, is that it might put pieces together in a way that makes statistical sense to the algorithm, but not any kind of human sense. These, of course, are what are entertainingly called “hallucinations”.
In a nutshell, an AI model can increase the distribution of knowledge, but not create new knowledge. It’s very good at proposing solutions to a problem someone else may have actually already solved in a fast and well-explained way, often saving you research time. This is good for efficiency and productivity, but not for innovation.
Real new knowledge or creativity is definitely not its cup of tea. That is the purview of human beings. I fear insufficient oversight in AI model adoption, coupled with over-reliance on data regurgitation as the primary method for answering questions, risks diminishing our collective human cognitive abilities, particularly critical thinking skills.
In closing, I feel it is vital that significant public bodies, such as the U.S. and E.U. governments, intervene to redress the private sector's disproportionate influence on AI development.
This requires strategic investment in AI technologies that advances the public interest (in fields like education, healthcare, and social sciences), alongside the implementation of judicious AI governance legislation to enhance governmental operational efficiency. I would encourage regulation to limit the adoption of these tools where their use is not appropriate and, in doing so, continue to guarantee space for human creativity in the arts, sciences, and innovation.

I see some examples in that direction are already popping up: the Italian university La Sapienza in Rome created an AI model tailored to the specific Italian economic landscape. It was trained on Italian data and aims to specifically support local regional governments and small to medium businesses. It’s called Minerva.
While this is encouraging, the fundamental missing step is computational power ownership by governments that would guarantee their independence from the big techs. This, of course, will require significant monetary investment.
I am eager for a future where public funds are used to support not only typical infrastructure projects such as roads and parks but also technological advancements, ultimately reinforcing our civil liberties.